
Code128とGS1-128って何が違うの?

もう随分と前になりますが、自動認識コラム「バーコード篇」第1回第2回辺りで、ISO/IEC規格やJIS規格が標準化している、謂わば“制式”バーコードをご紹介しました。「世界にはザッと100種類以上もあると言われるバーコードですが、その中で国際的に標準化されているコードシンボルは、それほど数多くはない」といったお話をしたと思います。その後「私たちの最も身近なバーコード(GTIN、JAN、ITF)について、その相互の関連性が私たちのような自動認識業界でも、曖昧なまま語られているケースがままあるように見受けられた」ので、その部分を少し突っ込んで解説させていただいきましたよね。
そうこうしていると、「Code128とGS1-128って、見た目が一緒に見えるんだけど」「この2種類のコード、いったい何が違うワケ?」といった疑問の声が寄せられたので、今回はこの2つのコード(Code128、GS1-128)について、述べてみたいと思います。
Code128
このバーコードシンボルは、世界で初めてUPCコードがスキャンされてから7年後の1981年、アメリカのコンピュータアイデンティックス(Computer Identix Inc.)という会社が開発したもの。ASCII(アスキー)コードの全128文字をバーコード化できるというのが最大の特長で、このバーコードシンボル名の由来でもあります。社名と全ASCIIコードということから推測された方もおられるのではないでしょうか。コンピューターへのデータ入力を想定して開発されたのだろうと思われます。
レギュレーション的には連続型のマルチレベルシンボルで、バー及びスペース幅は各4段階。3本のバーと3本のスペース、計6つのモジュールで1つの文字を構成しているのですが、このバーコードのややこしいのは他のバーコードと異なり、6モジュールで構成されたキャラクターに対応する文字が1対1の対応ではないんですね!どういうことかと言いますと、バーコードの始まりを示すスタートコードに3種類のスタートキャラクター(CODE-A、CODE-B、CODE-C)があって、このスタートキャラクター毎に同一のキャラクターに対応する文字が異なるんです。詳しくは表1の「Code128キャラクター構成」を参照していただきたいのですが、大雑把に言ってCODE-Aはフルアスキーに、CODE-Bはアルファニューメリック(記号、0~9の数字、アルファベット大文字26字)に、そしてCODE-Cは2桁の数値(00~99.)に対応するという理解でよろしいかと。
更にややこしいのが、上記のスタートキャラクター以外にコードセットキャラクター(これもCODE-A、CODE-B、CODE-Cの3種)とシフトキャラクターというものがあって、バーコードの途中にこれらのキャラクターが挿入されると、1つのCode128のバーコードの中で文字セットが変更されるんです!もう「デコーダー泣かせ、ここに極まる」って感じに、個人的には思うのですが・・・。おまけにシンボル長は可変長ときたもんです。ここまで来れば、もうどんなデータだってコード化出来ちゃいますよね?
またCODE-Cは1つのキャラクターで2桁の数字が表現できるので、非常に高密度なバーコードとなり、他のバーコードよりも省スペース化が図れるので、物流業界や産業界でも重宝されたそうです。
以上、ざっとCode128の概略を述べてきましたが、詳細まで踏み込むと紙幅がいくらあっても足らなくなりそうなので、この辺にしておきたいと思います。「いや、もっと詳しいレギュレーションも知りたい!」という方は、お手数ですが、JIS X 0504 (ISO/IEC 15417)に直接当たっていただくということでお許しください。m(__)m
あっ、Code128で欠かせないコードキャラクターを含むデータキャリア識別子も押さえておくなら、JIS X 0530 (ISO/IEC 15424)も併せてご覧くださいね。
表1:Code128キャラクター構成
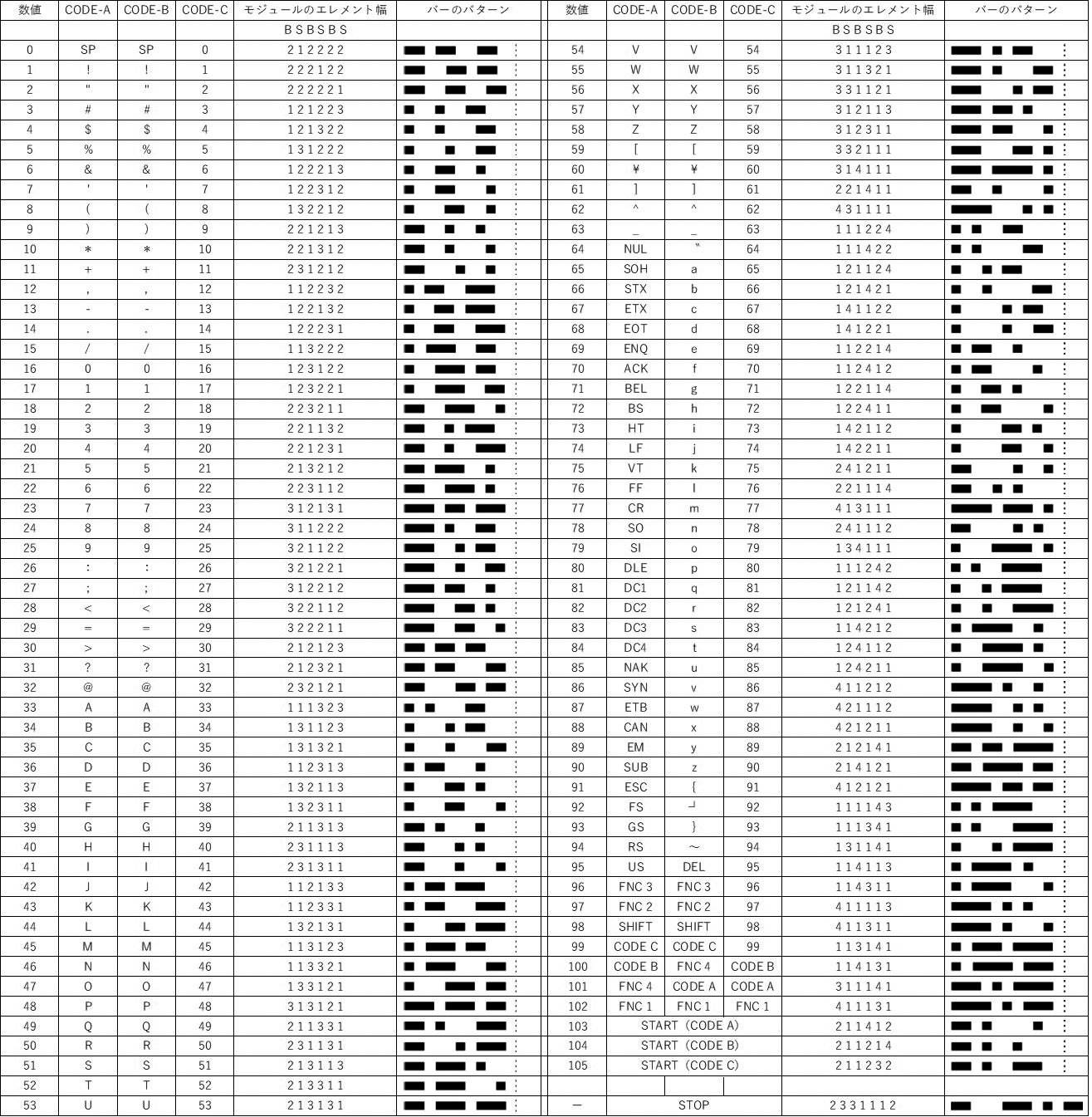
※ストップキャラクタは,13 モジュールから成り,4 本のバー及び 3 本のスペースをもつ。
これ以外のキャラクタの幅は,すべて 11 モジュールとなっており,バーから始まりスペースで終わる 6 エレメントから成り、各エレメントの幅は,1 モジュール幅から 4 モジュール幅までの範囲で変化。
B及びS欄にある数値が、シンボルキャラクタにおけるバー、スペースそれぞれのモジュール数を表す。
※右端の数値はシンボルキャラクターの値で、チェックデジットでの計算数値を表す。
※バーのパターン右の縦3点リーダーは次のキャラクタ―の開始位置を表している。
GS1-128
まず、最初に言っておきます。GS1-128はバーコードシンボル自体の規格ではありません!
実はこのGS1-128、Code128のシンボルを活用したアプリケーション規格なんです。なのでバーコードシンボル規格そのものはCode128の定義に準拠するものだと言えます。その上で流通業界全般のEDI連携を念頭に、産業界で求められる製品等の各データの表記方式をCode128上にアプリケーションとして規定しているバーコードだと言えるでしょう。だからこそGS1-128には必ずAI(GS1アプリケーション識別子)が必須で付加されているんです。※AIに付いては表2をご覧ください。
各社バーコードリーダーのスペックシートにある「可読コード一覧」などに、“Code128”は記載されていても“GS1-128”という記載がないのは、上記の理由からなんですね。
では、目の前にあるCode128シンボルが単なるCode128なのか、はたまたGS1-128なのかを、バーコードリーダーがどうやって見分けるかというと、このシンボルのスタートコードの直後にFNC1キャラクターが挿入されているかどうかに懸かっているんです。FNC1があれば「このCode128シンボルはGS1-128」ということになって、続いて出てくるAIや、そのAIのデータ長は、アプリケーションのお約束に従ってデコードされるという寸法になります。
日本国内では現在、①食肉標準物流バーコード ②公共料金等の代理収納 ③SCMラベル ④医療機器・医療用医薬品 などを中心に使用されています。③のSCMラベルというのは、大雑把に言うと、梱包した商品やオリコンなど納品箱に貼るバーコードのついた納品ラベルのことで、SCMはShipping Carton Markingのアクロニム(頭字語)。「出荷梱包表示ラベル」と訳されています。
アプリケーションの概略としては、
1)AI(アプリケーション識別子)とデータをセットで表示する。
2)複数のデータを連結できる。(ex. GTIN+消費期限、GTIN+シリアル番号など)
3)最大桁数は、数字48桁。それを越えた場合は、2段で表示する。(英字は、1文字を2桁に換算)
くらいを覚えておけばよろしいかと思います。
そして各AIの詳細は表2を見ていただくとして、数字2桁から4桁で表現される世界の消費財業界共通の識別コードだということと、大別して梱包識別、商品識別、計量識別、業務管理表示に分類されるということまで頭に入れておけば、GS1-128への理解としては十分であると筆者は思っています。
表2:GS1アプリケーション識別子(AI)一覧(例)
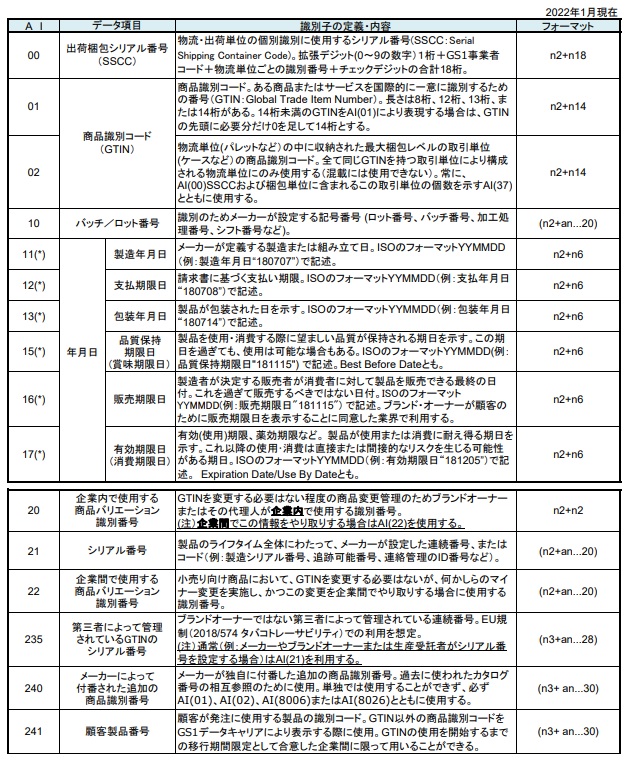
GS1アプリケーション識別子(AI)リスト_GS1 Japanサイトより転載
以上で、「Code128とGS1-128とはどういうモノで、違いは何か」を、少なくともイメージできるようになったのではないでしょうか。違いを中心に、イメージのし易さを重視して、説明を甚だ端折ってみましたが、如何でしたでしょう?
よろしければ下記のアンケートにご回答ください。